الگوریتم های هوش مصنوعی: همه آنچه باید بدانید
- بهدست: Admingfars
- دستهبندی: عمومی خبری

Warning: Undefined array key "https://www.gfars.ir/%d9%85%d9%82%d8%af%d9%85%d9%87-%d8%a7%db%8c-%d8%a8%d8%b1-%db%8c%d8%a7%d8%af%da%af%db%8c%d8%b1%db%8c-%d9%85%d8%a7%d8%b4%db%8c%d9%86%db%8c/" in /home3/lzcsublq/public_html/wp-content/plugins/wpa-seo-auto-linker/wpa-seo-auto-linker.php on line 192
الگوریتم های هوش مصنوعی: همه آنچه باید بدانید
همه ما میتوانیم موافق باشیم که هوش مصنوعی تأثیر زیادی بر اقتصاد جهان ایجاد کرده است و از آنجایی که با تولید حجم بیاندازه داده به رشد آن کمک میکنیم، به این کار ادامه خواهد داد. به لطف پیشرفت در الگوریتمهای هوش مصنوعی، میتوانیم با چنین دادههای بزرگی مقابله کنیم. در این پست وبلاگ، الگوریتم های مختلف هوش مصنوعی و نحوه استفاده از آنها برای حل مسائل دنیای واقعی را خواهید فهمید.
در اینجا لیستی از موضوعاتی است که پوشش داده خواهد شددر این پست:
هوش مصنوعی چیست؟
- یادگیری ماشینی چیست؟
- انواع یادگیری ماشینی
- انواع مسائل حل شده با استفاده از الگوریتم های هوش مصنوعی
- الگوریتم های هوش مصنوعی
- الگوریتم های طبقه بندی
- الگوریتم های رگرسیون
- الگوریتم های خوشه بندی
- الگوریتم های یادگیری گروهی
هوش مصنوعی چیست؟
به بیان ساده، هوش مصنوعی علم وادار کردن ماشین ها به تفکر و تصمیم گیری مانند انسان است.
از زمان توسعه الگوریتمهای پیچیده هوش مصنوعی ، توانسته است این کار را با ایجاد ماشینها و رباتهایی انجام دهد که در طیف گستردهای از زمینهها از جمله کشاورزی، مراقبتهای بهداشتی، رباتیک، بازاریابی، تجزیه و تحلیل تجاری و بسیاری موارد دیگر کاربرد دارند.
قبل از اینکه حرکت کنیمدر ادامه سعی می کنیم بفهمیم که یادگیری ماشین چیست و چگونه با هوش مصنوعی مرتبط است.
یادگیری ماشینی چیست؟
به طور کلی، یک الگوریتم مقداری ورودی می گیرد و از ریاضیات و منطق برای تولید خروجی استفاده می کند. در مقابل، الگوریتم هوش مصنوعی ترکیبی از هر دو ورودی و خروجی را به طور همزمان می گیرد تا داده ها را “یاد بگیرد” و خروجی هایی را در صورت داده شدن ورودی های جدید تولید کند.
این فرآیند یادگیری ماشین ها از داده ها همان چیزی است که ما آن را یادگیری ماشینی می نامیم.
الگوریتم هوش مصنوعی – الگوریتم های هوش مصنوعی – Edureka
یادگیری ماشینی زیر شاخه ای از هوش مصنوعی است که در آن سعی می کنیم با یادگیری داده های ورودی هوش مصنوعی را وارد معادله کنیم.
اگر کنجکاو هستید که درباره یادگیری ماشینی بیشتر بدانید، وبلاگهای زیر را بخوانید:
مقدمه ای بر یادگیری ماشینی: همه آنچه باید در مورد یادگیری ماشین بدانید
آموزش یادگیری ماشین برای مبتدیان
الگوریتم های یادگیری ماشین
ماشین ها می توانند دنبال کنندرویکردهای متفاوتی برای یادگیری بسته به مجموعه داده ها و مشکلی که در حال حل شدن است. در بخش زیر روشهای مختلف یادگیری ماشینها را خواهیم فهمید.
انواع یادگیری ماشینی
یادگیری ماشینی را می توان به روش های زیر انجام داد:
- یادگیری تحت نظارت
- یادگیری بدون نظارت
- یادگیری تقویتی
- آموزش گروهی
بیایید به طور خلاصه ایده هر نوع یادگیری ماشینی را درک کنیم.
یادگیری تحت نظارت چیست؟
در یادگیری نظارتی، همانطور که از نام آن به درستی پیداست، شامل یادگیری الگوریتم دادهها و ارائه پاسخهای صحیح یا برچسبهایی به دادهها میشود. این اساساً به این معنی است که کلاس ها یا مقادیری که باید پیش بینی شوند از همان ابتدا برای الگوریتم شناخته شده و به خوبی تعریف شده اند.
یادگیری بدون نظارت چیست؟
کلاس دیگر تحت آموزش بدون نظارت قرار می گیرد، که در آن، برخلاف روش های نظارت شده، الگوریتم پاسخ های صحیح یا اصلاً پاسخی ندارد، این به اختیار الگوریتم است که داده های مشابه را گرد هم آورده و آن ها را درک کند.
یادگیری تقویتی چیست؟
در کنار این دو کلاس برجسته، کلاس سومی به نام یادگیری تقویتی نیز داریم . همانطور که کودکان عموماً با پاداش دادن به آنها هنگام انجام کار درست یا تنبیه در صورت انجام کاری اشتباه، ایدهها، اصول خاصی را «تقویت میکنند»، در یادگیری تقویتی، با هر پیشبینی صحیح پاداشهایی به الگوریتم داده میشود و در نتیجه دقت را بالاتر میبرد.
در اینجا یک ویدیوی کوتاه است که توسط کارشناسان یادگیری ماشین ما ضبط شده است. این به شما کمک می کند تفاوت بین یادگیری تحت نظارت، بدون نظارت و تقویتی را درک کنید
یادگیری گروهی چیست؟
در حالی که سه کلاس بالا بیشتر زمینه ها را به طور جامع پوشش می دهند، ما گاهی اوقات هنوز در این موضوع قرار می گیریم که باید عملکرد مدل خود را افزایش دهیم. در چنین مواردی ممکن است منطقی باشد که از روشهای گروهی (که بعداً توضیح داده شد) برای بالا بردن دقت استفاده کنید.
حالا بیایید بفهمیم چگونهاز الگوریتم های هوش مصنوعی می توان برای حل انواع مختلف مسائل استفاده کرد.
همچنین در دوره های AI و ML ثبت نام کنید تا در این هوش مصنوعی و ML مهارت پیدا کنید.
انواع مسائل حل شده با استفاده از الگوریتم های هوش مصنوعی
الگوریتمهای هر دسته، در اصل، کار یکسانی را برای پیشبینی خروجیها با ورودیهای ناشناخته انجام میدهند، با این حال، در اینجا دادهها محرک کلیدی هنگام انتخاب الگوریتم مناسب هستند.
آنچه در زیر میآید خلاصهای از دستهبندیهای مشکلات یادگیری ماشین با مروری کوتاه بر همان موارد است:
- طبقه بندی
- پسرفت
- خوشه بندی
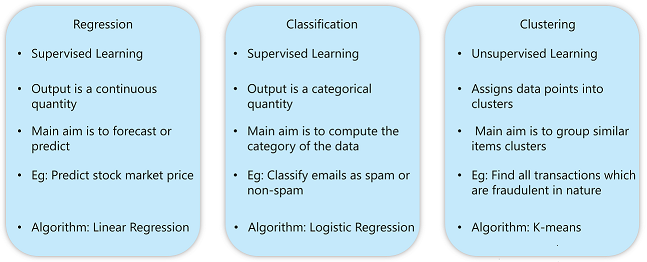
در اینجا جدولی وجود دارد که به طور موثر هر یک از این دسته از مشکلات را متمایز می کند.
نوع مسائل حل شده با استفاده از هوش مصنوعی – الگوریتم های هوش مصنوعی – Edureka
برای هر دسته ازوظایف، می توانیم از الگوریتم های خاصی استفاده کنیم. در بخش زیر خواهید فهمید که چگونه یک دسته از الگوریتم ها می توانند به عنوان راه حلی برای مسائل پیچیده استفاده شوند.
الگوریتم های هوش مصنوعی
همانطور که در بالا اشاره شد،الگوریتم های مختلف هوش مصنوعی را می توان برای حل یک دسته از مسائل استفاده کرد. در بخش زیر انواع مختلف الگوریتمهایی را که در طبقهبندی، رگرسیون و دستهبندی قرار میگیرند، خواهیم دید.
همچنین در دوره های AI ML ثبت نام کنید تا در هوش مصنوعی و یادگیری ماشین مهارت پیدا کنید.
الگوریتم های طبقه بندی
طبقه بندی، همانطور که از نام آن پیداست، عمل تقسیم متغیر وابسته (متغیری که سعی می کنیم پیش بینی کنیم) به کلاس ها و سپس پیش بینی یک کلاس برای یک ورودی داده شده است. این در دسته یادگیری ماشین نظارت شده قرار می گیرد، جایی که مجموعه داده ها برای شروع باید دارای کلاس باشند.
بنابراین، طبقهبندی در هر مکانی که ما نیاز به پیشبینی نتیجه داشته باشیم، از روی تعداد مجموعهای از نتایج ثابت و از پیش تعریفشده، وارد عمل میشود.
طبقه بندی از یک استفاده می کندآرایه ای از الگوریتم ها که تعدادی از آنها در زیر ذکر شده است
برنامه کارشناسی ارشد دوره یادگیری ماشین
- بیز ساده لوح
- درخت تصمیم
- جنگل تصادفی
- رگرسیون لجستیک
- ماشینهای بردار پشتیبانی
- K نزدیکترین همسایه ها
اجازه دهید آنها را تجزیه کنیم و ببینیم که در چه مواردی کاربرد دارند.
بیز ساده لوح
الگوریتم ساده بیز از قضیه بیز پیروی می کند که بر خلاف سایر الگوریتم های این لیست، از رویکرد احتمالی پیروی می کند. این اساسا به این معنی است که به جای پرش مستقیم به داده ها، الگوریتم مجموعه ای از احتمالات قبلی را برای هر یک از کلاس ها برای هدف شما تنظیم می کند.
هنگامی که داده ها را تغذیه می کنید، الگوریتم این احتمالات قبلی را به روز می کند تا چیزی به نام احتمال پسین را تشکیل دهد.
از این رو این می تواند در مواردی که باید پیش بینی کنید ورودی شما به لیست معینی از n کلاس تعلق دارد یا به هیچ یک از آنها تعلق ندارد، بسیار مفید باشد. این می تواند با استفاده از یک رویکرد احتمالی امکان پذیر باشد، زیرا احتمالات پرتاب شده برای تمام کلاس های n بسیار کم خواهد بود.
بیایید سعی کنیم این را با مثالی از فردی که گلف بازی می کند، بسته به عواملی مانند آب و هوای بیرون درک کنیم.
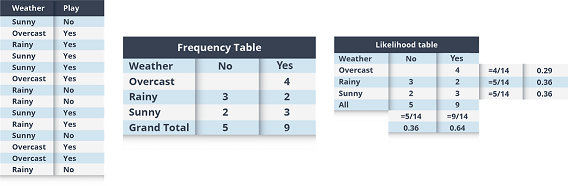
ما ابتدا سعی میکنیم فرکانسهایی را تولید کنیم که با آن رویدادهای خاص رخ میدهند، در این مورد، اگر هوا آفتابی، بارانی و غیره در بیرون است، سعی میکنیم فرکانسهای فردی که گلف بازی میکند را پیدا کنیم.
بیز ساده – الگوریتم های هوش مصنوعی – Edureka
با استفاده از این فرکانس ها، احتمالات اولیه یا اولیه خود را تولید می کنیم (به عنوان مثال، احتمال ابری 0.29 است در حالی که احتمال عمومی بازی 0.64 است)
در مرحله بعد، احتمالات پسینی را ایجاد می کنیم، جایی که سعی می کنیم به سوالاتی مانند “احتمال اینکه بیرون آفتابی باشد و فرد گلف بازی کند چقدر است؟” پاسخ دهیم.
ما در اینجا از فرمول بیزی استفاده می کنیم،
P(بله | آفتابی) = P( آفتابی | بله) * P(بله) / P (آفتابی)
در اینجا P (آفتابی | بله) = 3/9 = 0.33، P(آفتابی) = 5/14 = 0.36، P (بله) = 9/14 = 0.64
میتونی بریاز طریق این راهنمای جامع برای ساده لوح بیزوبلاگی برای کمک به درک ریاضیات پشت بیز ساده لوح.
درخت تصمیم
درخت تصمیم اساساً می تواند به عنوان یک ساختار درختی فلوچارت مانند خلاصه شود که در آن هر گره خارجی آزمایشی را بر روی یک ویژگی نشان می دهد و هر شاخه نشان دهنده نتیجه آن آزمایش است. گره های برگ حاوی برچسب های واقعی پیش بینی شده هستند. ما از ریشه درخت شروع می کنیم و به مقایسه مقادیر ویژگی ها ادامه می دهیم تا به یک گره برگ برسیم.
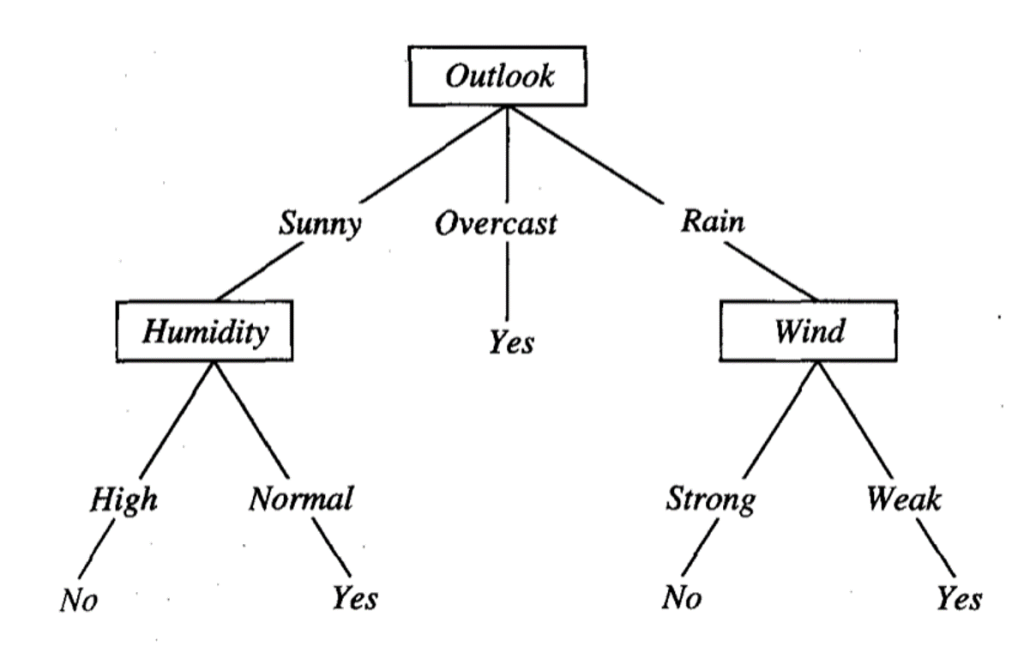
درختان تصمیم – الگوریتم های هوش مصنوعی – Edureka
ما از این طبقه بندی کننده در هنگام مدیریت داده های با ابعاد بالا و زمانی که زمان کمی برای آماده سازی داده ها صرف شده است استفاده می کنیم. با این حال، یک کلمه احتیاط – آنها تمایل به بیش از حد مناسب دارند و حتی با وجود تفاوت های جزئی در داده های آموزشی، مستعد تغییر شدید هستند.
شما می توانید از طریقاین وبلاگ ها برای کسب اطلاعات بیشتر در مورد درخت تصمیم:
راهنمای کامل الگوریتم درخت تصمیم
درخت تصمیم: چگونه یک درخت تصمیم کامل بسازیم؟
جنگل تصادفی
این را به عنوان کمیته ای از درختان تصمیم در نظر بگیرید، جایی که هر درخت تصمیم زیرمجموعه ای از ویژگی های داده ها را تغذیه می کند و بر اساس آن زیر مجموعه پیش بینی می کند. میانگین آرای تمامی درختان تصمیم گیری در نظر گرفته شده و پاسخ داده می شود.
مزیت استفاده از Random Forest این است که مشکل بیش از حد برازش را که در درخت تصمیم گیری مستقل وجود داشت را کاهش می دهد و منجر به طبقه بندی بسیار قوی تر و دقیق تر می شود.
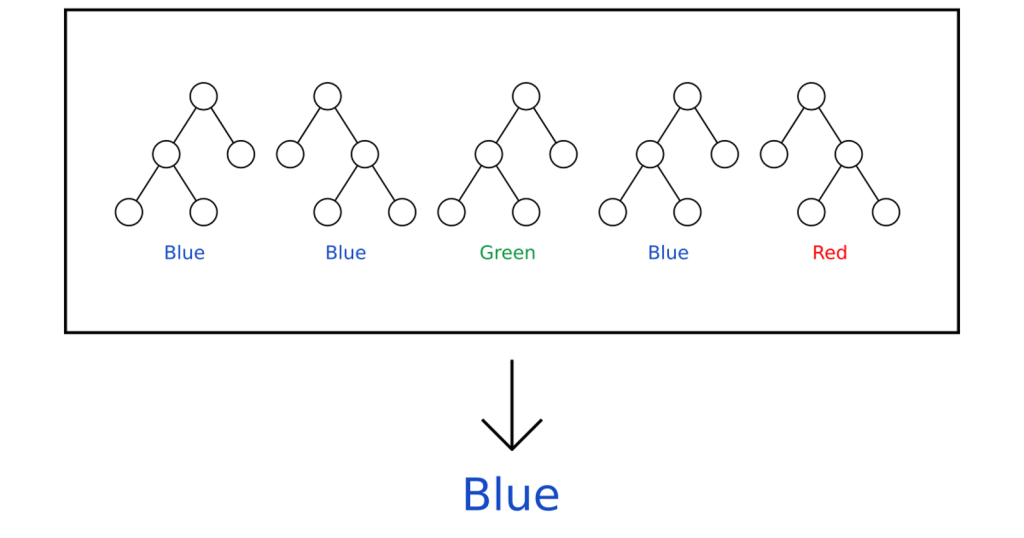
جنگل تصادفی – الگوریتمهای هوش مصنوعی – Edureka
همانطور که در تصویر بالا می بینیم، ما 5 درخت تصمیم داریم که سعی می کنند یک رنگ را طبقه بندی کنند. در اینجا 3 مورد از این 5 درخت تصمیم آبی را پیشبینی میکنند و دو درخت خروجی متفاوتی دارند، یعنی سبز و قرمز. در این حالت، میانگین تمام خروجی ها را می گیریم که آبی را به عنوان بالاترین وزن می دهد.
اینجا یک وبلاگ استدر طبقه بندی جنگل تصادفیکه به شما در درک عملکرد الگوریتم جنگل تصادفی و نحوه استفاده از آن برای حل مسائل دنیای واقعی کمک می کند.
رگرسیون لجستیک
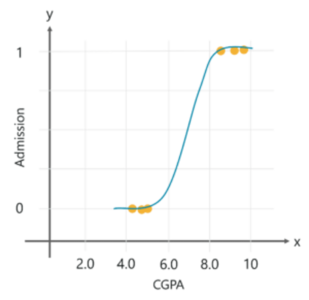
این روشی است که عمدتاً برای کارهای طبقه بندی باینری است. اصطلاح “لجستیک” از تابع logit که در این روش طبقه بندی استفاده می شود، می آید. تابع لجستیک که تابع سیگموئید نیز نامیده میشود، یک منحنی S شکل است که میتواند هر عدد با ارزش واقعی را بگیرد و آن را بین 0 و 1 ترسیم کند، اما هرگز دقیقاً در آن حدود نیست.
رگرسیون لجستیک – الگوریتمهای هوش مصنوعی – Edureka
بیایید فرض کنیم که برادر کوچک شما در حال تلاش برای ورود به دبیرستان است، و شما می خواهید پیش بینی کنید که آیا او در موسسه رویایی خود پذیرفته می شود یا خیر. بنابراین، بر اساس CGPA وی و داده های گذشته، می توانید از رگرسیون لجستیک برای پیش بینی نتیجه استفاده کنید.
رگرسیون لجستیک به شما امکان می دهد مجموعه ای از متغیرها را تجزیه و تحلیل کنید و یک نتیجه طبقه بندی شده را پیش بینی کنید. از آنجایی که در اینجا باید پیش بینی کنیم که آیا او به دست می آورد یا خیردر مدرسه یا نه، که یک مشکل طبقه بندی است، رگرسیون لجستیک ایده آل خواهد بود.
رگرسیون لجستیک برای پیش بینی ارزش خانه، ارزش طول عمر مشتری در بخش بیمه و غیره استفاده می شود.
ماشین بردار پشتیبانی
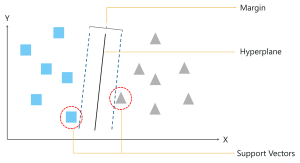
یک SVM منحصربهفرد است، به این معنا که سعی میکند دادهها را با حاشیههای بین دو کلاس تا جایی که امکان دارد مرتب کند. به این تفکیک حاشیه حداکثر می گویند.
نکته دیگری که در اینجا باید به آن توجه داشت این واقعیت است که SVM ها تنها بردارهای پشتیبان را در هنگام ترسیم هایپرپلن در نظر می گیرند، بر خلاف رگرسیون خطی که از کل مجموعه داده برای این منظور استفاده می کند. این باعث می شود SVM در شرایطی که داده ها در ابعاد بالایی هستند بسیار مفید باشد.
بیایید سعی کنیم این را با یک مثال درک کنیم. در شکل زیر باید نقاط داده را به دو کلاس مختلف (مربع و مثلث) طبقه بندی کنیم.
ماشین بردار پشتیبانی – الگوریتمهای هوش مصنوعی – Edureka
بنابراین، با کشیدن یک ابر صفحه تصادفی شروع میکنید و سپس فاصله بین ابر صفحه و نزدیکترین نقاط داده از هر کلاس را بررسی میکنید. این نزدیکترین نقاط داده به ابر صفحه به عنوان بردارهای پشتیبانی شناخته می شوند . و نام ماشین بردار پشتیبان از همین جا آمده است.
آموزش هوش مصنوعی
ابرصفحه بر اساس این بردارهای پشتیبان رسم می شود و یک ابر صفحه بهینه حداکثر فاصله را از هر یک از بردارهای پشتیبان خواهد داشت . و این فاصله بین ابرصفحه و بردارهای پشتیبان به عنوان حاشیه شناخته می شود .
به طور خلاصه، SVM برای طبقه بندی داده ها با استفاده از یک ابر صفحه استفاده می شود، به طوری که فاصله بین ابر صفحه و بردارهای پشتیبان برابر است.بیشترین.
برای کسب اطلاعات بیشتر در مورد SVM، می توانید از طریق این وبلاگ با استفاده از SVM برای پیش بینی بیماری های قلبی مراجعه کنید.
K نزدیکترین همسایه ها
KNN یک ناپارامتریک است (در اینجا ناپارامتریک فقط یک اصطلاح فانتزی است که اساساً به این معنی است که KNN هیچ فرضی در مورد توزیع داده های اساسی نمی کند)، الگوریتم یادگیری تنبل (در اینجا تنبلی به این معنی است که مرحله “آموزش” نسبتاً کوتاه است) .
هدف آن استفاده از یک دسته کامل از نقاط داده است که به چندین کلاس جدا شده اند تا طبقه بندی یک نقطه نمونه جدید را پیش بینی کند.
نکات زیر به عنوان یک نمای کلی از عملکرد کلی الگوریتم عمل می کند:
- یک عدد صحیح مثبت N به همراه یک نمونه جدید مشخص می شود
- ما N ورودی را در پایگاه داده خود انتخاب می کنیم که نزدیکترین آنها به نمونه جدید است
- ما رایج ترین طبقه بندی این مدخل ها را پیدا می کنیم
- این طبقه بندی است که ما به نمونه جدید می دهیم
با این حال، برخی از معایب استفاده از KNN وجود دارد. این نکات منفی عمدتاً حول این واقعیت است که KNN روی ذخیره کل مجموعه داده و مقایسه نقاط جدید با موارد موجود کار می کند. این بدان معناست که با افزایش مجموعه آموزشی ما فضای ذخیره سازی افزایش می یابد. این همچنین به این معنی است که زمان تخمین متناسب با تعداد امتیازات آموزشی افزایش می یابد.
وبلاگ های زیر به شما کمک می کند تا بفهمید که چگونه KNNالگوریتم به صورت عمیق کار می کند:
اجرای عملی الگوریتم KNN در R
الگوریتم K-نزدیکترین همسایگان با استفاده از پایتون
حال بیایید بفهمیم که چگونه می توان مسائل رگرسیون را با استفاده از الگوریتم های رگرسیون حل کرد.
الگوریتم های رگرسیون
در مورد مشکلات رگرسیون، خروجی یک کمیت پیوسته است . به این معنی که در مواردی که متغیر هدف یک متغیر پیوسته است می توانیم از الگوریتم های رگرسیون استفاده کنیم. این در دسته یادگیری ماشین نظارت شده قرار می گیرد، جایی که مجموعه داده ها برای شروع باید دارای برچسب باشند.
رگرسیون خطی
رگرسیون خطی ساده ترین و موثرترین الگوریتم رگرسیون است. برای اندازهگیری کیفیتهای واقعی (هزینه خانه، تعداد تماسها، همه معاملات و غیره) با توجه به متغیر(های) سازگار استفاده میشود. در اینجا، ما با برازش بهترین خط، بین عوامل آزاد و بخش ارتباط برقرار میکنیم. این بهترین خط به عنوان خط رگرسیون شناخته می شود و با یک شرط مستقیم Y= a *X + b صحبت می شود.
رگرسیون خطی – الگوریتمهای هوش مصنوعی – Edureka
اجازه دهید در اینجا یک مثال ساده برای درک رگرسیون خطی بیاوریم.
در نظر بگیرید که به شما این چالش داده شده است که وزن یک فرد ناشناس را تنها با نگاه کردن به آنها تخمین بزنید. بدون هیچ ارزش دیگری، این ممکن است کار نسبتاً دشواری به نظر برسد، اما با استفاده از تجربیات گذشته خود میدانید که به طور کلی هر چه بلندتر باشد، در مقایسه با یک فرد کوتاهقدتر با همان هیکل سنگینتر است. این رگرسیون خطی است، در واقع!
با این حال، رگرسیون خطی به بهترین وجه در رویکردهایی که شامل تعداد کم ابعاد هستند استفاده می شود. همچنین، هر مشکلی به صورت خطی قابل تفکیک نیست.برخی از محبوب ترین کاربردهای رگرسیون خطی در پیش بینی سبد مالی، پیش بینی حقوق و دستمزد، پیش بینی املاک و مستغلات و ترافیک در رسیدن به ETA است.حالا وقتهدر مورد چگونگی حل مسائل خوشه بندی با استفاده از الگوریتم K-means بحث کنید. قبل از آن، بیایید درک کنیم که خوشه بندی چیست.
الگوریتم های خوشه بندی
ایده اصلی پشت خوشه بندی این است که ورودی را به دو یا چند خوشه بر اساس شباهت ویژگی ها اختصاص دهیم. این در دسته یادگیری ماشینی بدون نظارت قرار می گیرد، جایی که الگوریتم الگوها و بینش های مفید را از داده ها بدون هیچ راهنمایی می آموزد (مجموعه داده برچسب گذاری شده).
برای مثال، خوشهبندی بینندگان در گروههای مشابه بر اساس علایق، سن، جغرافیا و غیره را میتوان با استفاده از الگوریتمهای یادگیری بدون نظارت مانند K-Means Clustering انجام داد.
K-Means Clustering
K-means احتمالا ساده ترین رویکرد یادگیری بدون نظارت است. ایده در اینجا این است که نقاط داده مشابه را با هم جمع آوری کنیم و آنها را در قالب یک خوشه به یکدیگر متصل کنیم. این کار را با محاسبه مرکز گروه نقاط داده انجام می دهد.
برای انجام خوشه بندی موثر، k-means فاصله بین هر نقطه از مرکز خوشه را ارزیابی می کند. بسته به فاصله بین نقطه داده و مرکز، داده ها به نزدیکترین خوشه اختصاص داده می شوند. هدف از خوشه بندی تعیین گروه بندی ذاتی در مجموعه ای از داده های بدون برچسب است.
K-means – الگوریتم های هوش مصنوعی – Edureka
“K” در K-means مخفف تعداد خوشه های تشکیل شده است. تعداد خوشهها (در اصل تعداد کلاسهایی که نمونههای جدید داده شما میتوانند در آنها قرار بگیرند) توسط کاربر تعیین میشود.
K-means عمدتاً در مواردی استفاده می شود که مجموعه داده ها دارای نقاط متمایز و به خوبی از یکدیگر هستند، در غیر این صورت، خوشه ها از هم دور نخواهند بود و آنها را نادرست می کند. همچنین در مواردی که مجموعه داده دارای مقادیر پرت بالایی است یا مجموعه داده غیرخطی است، باید از K-means اجتناب شود.
بنابراین این مختصری در مورد الگوریتم K-means بود، برای کسب اطلاعات بیشتر می توانید این محتوای ضبط شده توسط یادگیری ماشین ما را مرور کنید.کارشناسان
K به معنای الگوریتم خوشه بندی | ادورکا
در این ویدیو با مفاهیم خوشه بندی K-Means و اجرای آن با استفاده از پایتون آشنا می شوید.
الگوریتم های یادگیری گروهی
در مواردی که دادهها فراوان هستند و دقت پیشبینی از ارزش بالایی برخوردار است، الگوریتمهای تقویت کننده وارد تصویر میشوند.
این سناریو را در نظر بگیرید، شما یک درخت تصمیم دارید که بر روی یک مجموعه داده به همراه یک دسته کامل از تنظیم هایپرپارامتر از قبل انجام شده است، با این حال، دقت نهایی هنوز کمی کمتر از آنچه می خواهید است. در این مورد، در حالی که ممکن است به نظر برسد که چیزهای ممکن برای امتحان تمام شده است، یادگیری گروهی به کمک می آید.
مجموعه یادگیری – الگوریتم های هوش مصنوعی – Edure
دسته های روز هفته / آخر هفته
شما دو روش مختلف دارید که در این مورد می توانید از یادگیری گروهی برای افزایش دقت خود استفاده کنید. بگذارید بگوییم درخت تصمیم شما در مجموعه ای از مقادیر تست ورودی شکست خورده است، کاری که اکنون انجام می دهید این است که یک مدل درخت تصمیم جدید را آموزش دهید و به آن مقادیر تست ورودی که مدل قبلی شما با آنها دست و پنجه نرم می کرد وزن بیشتری بدهید. این به عنوان Boosting نیز نامیده می شود ، که در آن درخت اولیه ما می تواند به طور رسمی به عنوان یک یادگیرنده ضعیف بیان شود، و اشتباهات ناشی از آن مدل راه را برای یک مدل بهتر و قوی تر هموار می کند.
راه دیگری برای نزدیک شدن به این موضوع این است که به سادگی یک دسته از درختان را به طور همزمان آموزش دهید (این کار را می توان نسبتاً سریع و به صورت موازی انجام داد) و سپس خروجی ها را از هر درخت و میانگین گیری آنها را انجام دهید. بنابراین، اگر پس از آموزش 10 درخت، فرض کنید که 6 درخت به ورودی مثبت و 4 درخت پاسخ منفی دهند، خروجی مورد نظر شما مثبت است. این به طور رسمی به عنوان Bagging شناخته می شود.
آنها برای کاهش سوگیری و واریانس در تکنیک های یادگیری نظارت شده استفاده می شوند. الگوریتم های تقویت کننده زیادی وجود دارد که در زیر به چند مورد از آنها پرداخته شده است:
افزایش گرادیان
Gradient Boosting یک الگوریتم تقویتی است که برای پیش بینی با قدرت پیش بینی بالا با داده های زیادی سروکار داریم. چندین پیش بینی ضعیف یا متوسط را برای ایجاد پیش بینی قوی ترکیب می کند. این الگوریتمهای تقویتکننده بهشدت برای اصلاح مدلها در مسابقات علم داده استفاده میشوند.
در اینجا، ما یک مدل “بهینه” یا بهترین را در نظر می گیریم، بنابراین اساساً مدل ما در فاصله ای از مدل “بهینه” قرار دارد. کاری که اکنون انجام می دهیم این است که از ریاضیات گرادیان استفاده کنیم و سعی کنیم مدل خود را به فضای بهینه نزدیک کنیم.
XGBoost
XGBoost با توجه به قدرت پیشبینی بسیار بالای خود، یکی از الگوریتمهای مورد استفاده برای افزایش دقت است، زیرا شامل الگوریتمهای یادگیری خطی و درختی است که آن را 10 برابر سریعتر از بسیاری از تکنیکهای تقویتی میکند.
وقتی صحبت از هکاتون می شود، این الگوریتم جام مقدس است، جای تعجب نیست که CERN از آن در مدل طبقه بندی سیگنال های برخورد دهنده بزرگ هادرون استفاده کرده است.
اگر میخواهید درباره تقویت یادگیری ماشینی اطلاعات بیشتری کسب کنید، میتوانید این وبلاگ راهنمای جامع تقویت الگوریتمهای یادگیری ماشینی را مرور کنید .
بنابراین با این کار، به پایان این وبلاگ الگوریتم های هوش مصنوعی می رسیم. اگر میخواهید درباره هوش مصنوعی بیشتر بدانید، میتوانید این وبلاگها را بخوانید:
هوش مصنوعی – چیست و چگونه مفید است؟
راهنمای جامع هوش مصنوعی با پایتون
آموزش هوش مصنوعی: همه آنچه باید در مورد هوش مصنوعی بدانید
هوش مصنوعی در مقابل یادگیری ماشینی در مقابل یادگیری عمیق
برنامه های کاربردی هوش مصنوعی: 10 برنامه برتر هوش مصنوعی دنیای واقعی
اگر می خواهید برای یک دوره کامل در زمینه هوش مصنوعی و یادگیری ماشین ثبت نام کنید، Edureka دارای یک برنامه کارشناسی ارشد مهندسی یادگیری ماشین است که شما را در تکنیک هایی مانند یادگیری نظارت شده، یادگیری بدون نظارت و پردازش زبان طبیعی ماهر می کند. این شامل آموزش در مورد آخرین پیشرفتها و رویکردهای فنی در هوش مصنوعی و یادگیری ماشینی مانند یادگیری عمیق، مدلهای گرافیکی و یادگیری تقویتی است



بدون دیدگاه